
Projet : Prédiction de sentiment (tweet)
- Fabien Cappelli
- 21 mai 2025
- 6 min de lecture

Dernière mise à jour : 27 mai 2025
Contexte et Objectif du Projet
Le projet vise à créer un prototype fonctionnel d'une Intelligence Artificielle capable de prédire précisément le sentiment (positif ou négatif) associé à des tweets en langue anglaise. À défaut de données internes, le projet repose sur un ensemble massif de données open source regroupant environ 1 600 000 tweets annotés avec des sentiments binaires (positifs et négatifs). L’objectif final est de développer un modèle performant, accessible via une API cloud, et utilisable par une interface web intuitive.
Principes du MLOps
Le but sera aussi ici de mettre en place une démarche en alignement avec les grands principes du MLOps, autant que possible.
1. Automatisation du cycle de vie ML
Toutes les étapes du cycle de vie d’un modèle de machine learning, de l’exploration des données au déploiement, en passant par l’entraînement et la surveillance, doivent être automatisées et orchestrées.
Cela comprend la collecte des données, la préparation, l’entraînement, le test, le déploiement, la surveillance et la maintenance.
Comme on le verra ensuite, tout cela sera géré dans notre projet via MLFlow et GitHub.
2. Intégration continue et déploiement continu (CI/CD)
MLOps adapte les pratiques de DevOps au machine learning, en mettant l’accent sur l’intégration continue (tests automatisés, validation du code et des données) et le déploiement continu (mise en production rapide et fiable des modèles).
Cela sera géré ici principalement via GitHub Actions, mais aussi via DockerHub et Azure.
3. Gestion des versions
On veut être capable de versionner non seulement le code, mais aussi les données, les modèles et les configurations pour garantir la reproductibilité et le suivi des évolutions (expériences, modèles déployés, jeux de données utilisés).
Cela sera géré dans notre projet via MLFlow et GitHub.
4. Surveillance et traçabilité
Mise en place d’outils pour surveiller les performances des modèles en production (précision, dérive de données, dérive de concept).
Traçabilité des modèles : savoir à tout moment quel modèle est déployé, avec quelles données, et comment il a été entraîné.
Nous gèrerons les alertes via Azure Insights, et la traçabilité via GitHub et MLFlow
5. Collaboration interdisciplinaire
Faciliter la collaboration entre data scientists, ingénieurs ML, développeurs, et opérations IT.
Utilisation de plateformes centralisées, de pipelines partagés, de gestion commune des environnements.
6. Scalabilité et reproductibilité
Rendre les pipelines ML scalables (adaptés aux grands volumes de données) et reproductibles (mêmes résultats avec les mêmes entrées, possibilité de rejouer une expérience à l’identique).
7. Sécurité et conformité
Assurer la sécurité des données et des modèles, et la conformité réglementaire (gestion des accès, logs, audit).
Préparation et Exploration des Données
Les données initiales incluaient non seulement les textes des tweets mais également des métadonnées comme l'identifiant utilisateur et la date de publication.

La première étape, dans ce type de projet, consiste à inspecter et valider les données pour identifier les éventuelles anomalies ou erreurs de classification. J'ai rapidement détecté des tweets identiques classifiés de façon incohérente, dont voici quelques exemples :

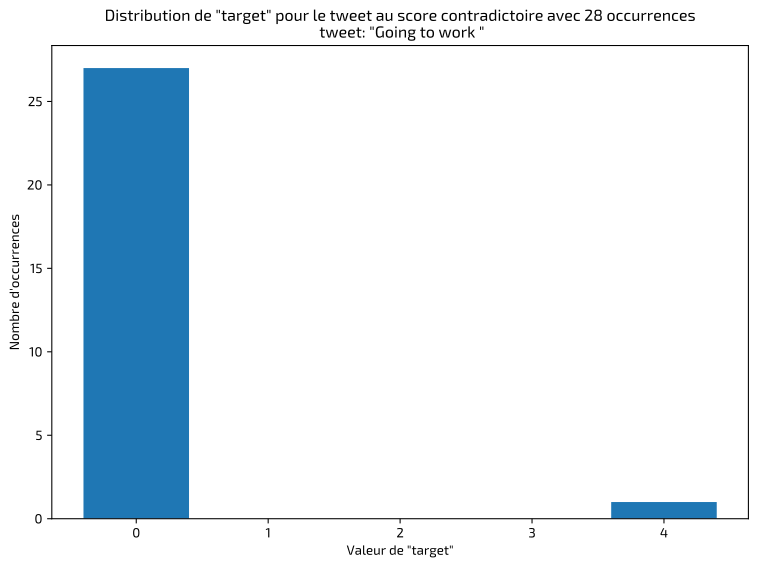

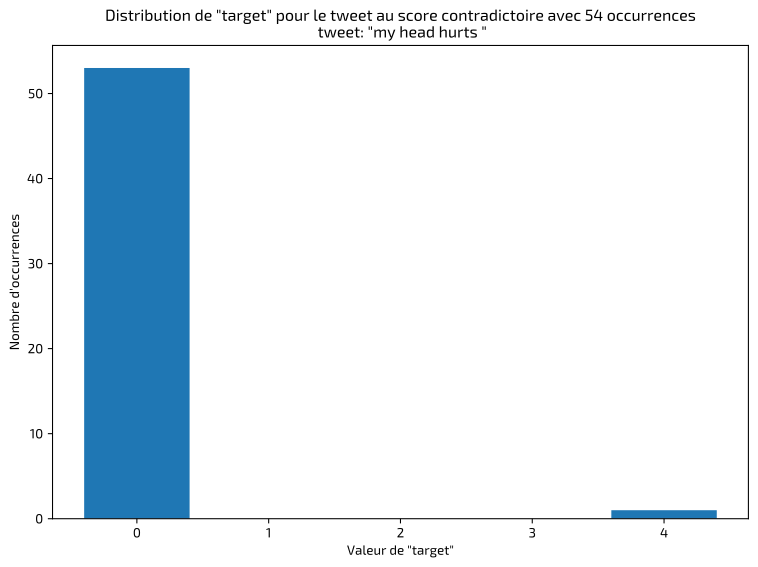

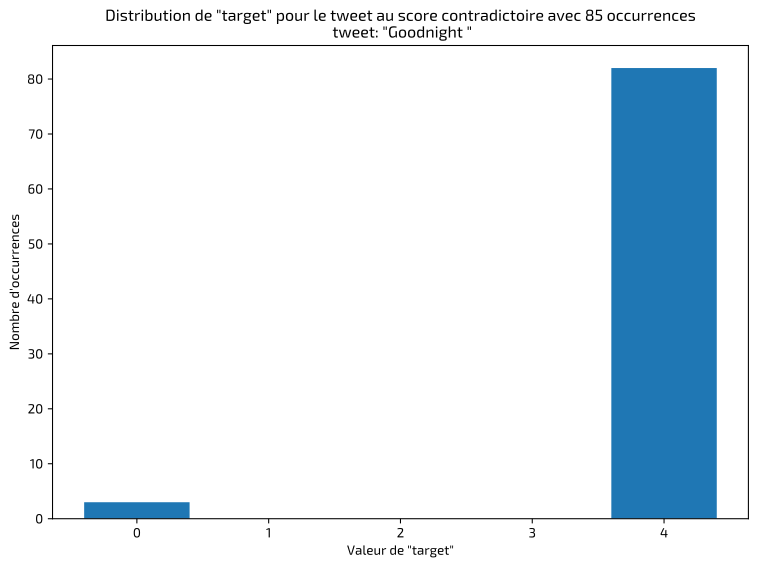

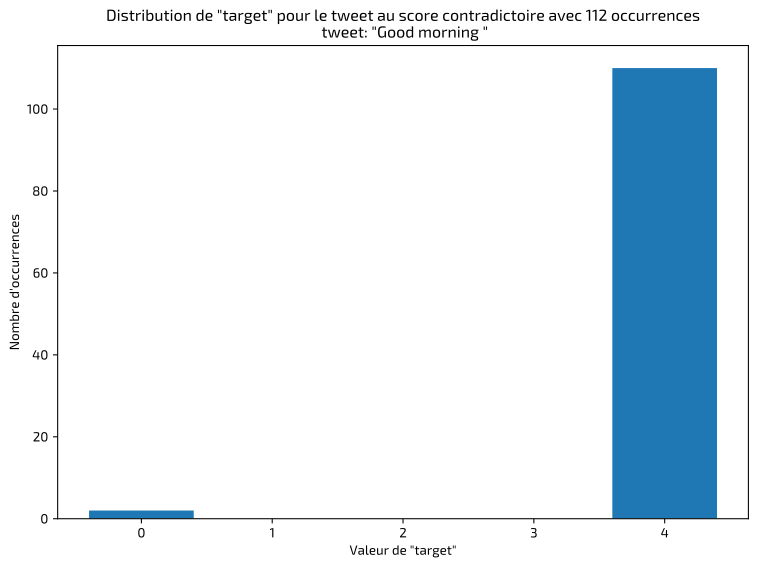
J'ai dans ces cas-là conservé les annotations majoritaires. Le résultat final montre un jeu de données équilibré entre les classes positives et négatives :

Modélisations Expérimentées
Plusieurs approches ont été méthodiquement explorées pour identifier la solution la plus efficace et adaptée à cette problématique spécifique.
Recherche des meilleurs hyperparamètres
Lorsqu’on entraîne un modèle d’intelligence artificielle, il existe des paramètres appelés hyperparamètres. Ce sont des réglages “externes” au modèle : par exemple, la taille du lot d’entraînement (batch size), le taux d’apprentissage (learning rate), le nombre d’epochs, etc.
Ces hyperparamètres ne sont pas appris par le modèle : ce sont des choix que l’on doit faire AVANT l’entraînement, et leur valeur peut avoir un grand impact sur la performance finale.
La grid search (ou recherche sur grille) est une méthode systématique pour trouver les meilleurs hyperparamètres.
Critères et Méthodes d'Évaluation
Les performances des modèles ont été évaluées via plusieurs métriques rigoureuses :
Accuracy : Pourcentage de bonnes réponses sur l’ensemble des prédictions. Fiable dans ce cas précis grâce à l'équilibre du jeu de données. C'est la métrique utilisée ici pour choisir les meilleurs hyperparamètres.
F1-score : Cette métrique équilibre la capacité à trouver tous les cas positifs et à ne pas faire de fausses alertes.
ROC AUC : Pour mesurer la capacité du modèle à correctement ordonner les prédictions selon leur probabilité.
Temps d'inférence : Indicateur pratique de la complexité et du poids opérationnel du modèle choisi.
Prétraitements des Données et Sélection Raisonnée du Vocabulaire
Différents prétraitements furent explorés, allant d'un simple nettoyage (retrait des URLs, hashtags, mentions) à des méthodes plus avancées (lemmatisation, tokenisation avec spaCy). Une attention particulière fut portée à la sélection du vocabulaire, en déterminant de manière raisonnée le nombre de mots à inclure pour couvrir efficacement le corpus tout en limitant le bruit et la complexité inutile.
Types de modèles
Modèle Classique (Régression Logistique et TF-IDF)
Cette méthode traditionnelle met en jeu deux étapes principales : la vectorisation TF-IDF des tweets, qui pondère l'importance des mots en fonction de leur fréquence dans les documents et leur rareté dans l'ensemble du corpus, suivie par l'utilisation d'une régression logistique pour classifier les tweets en catégories positives ou négatives.
La recherche d'hyperparamètres ciblait principalement la fréquence minimale et maximale des mots, la taille des n-grammes, et le paramètre de régularisation (C) pour éviter le sur-apprentissage.
Réseau Neuronal Convolutif (CNN)
L'approche CNN se distingue par sa capacité à détecter des motifs dans les données textuelles. Le modèle utilise une couche d'embedding pour transformer les mots en vecteurs, suivie de deux couches convolutionnelles (Conv1D) pour capturer les motifs caractéristiques des expressions typiques du sentiment positif ou négatif. Un pooling global max résume les motifs détectés avant qu'une couche dense et une couche finale de sortie ne fournissent la prédiction finale.
Utilisation d'Embeddings Pré-entraînés
Si j'ai laissé dans un premier temps mon réseau construire ses propres embeddings, j'ai aussi testé deux embeddings pré-entraînés, pour capitaliser sur la richesse sémantique existante :
GloVe Twitter : spécialement conçu pour capturer les particularités linguistiques des réseaux sociaux.
GoogleNews Word2Vec : plus généraliste, performant sur un vocabulaire diversifié mais moins adapté à l'informalité typique des tweets.
Les hyperparamètres critiques pour cette approche incluaient la dimension de l'embedding, le nombre de filtres, la taille du noyau, la proportion de dropout, ainsi que le learning rate et le batch size.
Réseau Neuronal Récurrent (RNN – LSTM Bidirectionnel)
L'architecture LSTM bidirectionnelle est particulièrement adaptée à l'analyse contextuelle des phrases longues, permettant de prendre en compte le contexte précédant et suivant chaque mot. Deux couches bidirectionnelles ont été utilisées pour extraire et consolider les informations contextuelles nécessaires à une classification précise.
Les hyperparamètres testés incluaient le nombre d'unités LSTM, déterminant la capacité de mémoire du modèle, ainsi que le learning rate et le batch size.
Modèle Transformer (DistilBERT)
DistilBERT, une version compacte et optimisée de BERT, utilise un mécanisme d'attention pour saisir les nuances et dépendances longues dans le texte. Ce modèle, particulièrement performant sur le langage informel des réseaux sociaux, fut affiné spécifiquement sur les données de ce projet.
Les hyperparamètres sélectionnés pour optimisation furent principalement le learning rate et le batch size.
Utilisation Professionnelle d'MLFlow via DagsHub
J'ai utilisé MLFlow, via la plateforme DagsHub, pour suivre de manière systématique toutes les expériences réalisées :
Archivage automatique des paramètres d'entraînement, des métriques et des résultats.
Comparaison rapide et précise des performances des différents modèles et essais.
Facilitation de la reproductibilité et traçabilité des expériences.
Performances et sélection Finale du Modèle
Voici le comparatif des performances de nos tests :



DistilBERT a finalement été retenu grâce à ses performances supérieures, sa capacité à saisir les subtilités linguistiques, et une taille de modèle qui reste malgré tout raisonnable pour le déploiement. Le second choix serait le RNN Brut - sans preprocessing des données.
Déploiement Technique et Automatisation via API
Une API et une UI furent développées pour assurer modularité et efficacité opérationnelle :
Backend avec FastAPI : gère les requêtes prédictives et répond avec la classe prédite ainsi que les probabilités associées.
Frontend avec Streamlit : interface utilisateur interactive, incluant une fonctionnalité d'alerte permettant aux utilisateurs de signaler des erreurs de classification.
Elles furent encapsulées dans des conteneurs Docker pour garantir la portabilité et le fonctionnement uniforme sur différentes plateformes.
Automatisation et Déploiement Continu
GitHub fut utilisé pour la gestion du code source, tandis que GitHub Actions automatisa les tests unitaires et la création des images Docker. Ces images sont ensuite stockées sur DockerHub avant d'être déployées automatiquement sur Azure, garantissant ainsi une intégration et un déploiement continus (CI/CD) robustes.
Système d’Alerte
Azure Insights complète cette architecture en fournissant des alertes en cas d'incidents fréquents ou de dysfonctionnements répétés signalés via l'API frontend. Dans notre exemple, trois tweets signalés comme mal classés en moins de cinq minutes envoie une alerte par mail et SMS sur ma boîte et mon téléphone.
Suivi Post-Déploiement
Les actions préconisées pour un suivi post-déploiement et une utilisation en production sont les suivantes :
En cas d'augmentation significative des alertes, une revue humaine des données peut être déclenchée pour déterminer si un réentraînement du modèle est nécessaire. Un seuil minimal de 0,1 à 1 % du corpus initial (soit entre 1 600 et 16 000 tweets) est fixé pour justifier un réentraînement.
(1534 mots)
Commentaires